We’re hiring a Software Engineer at RebelCode. Posted the job, shared it around, and then watched 200+ applications roll in over a couple of weeks. Great problem to have, right?
Except now I’m staring at a spreadsheet, trying to remember if candidate #34 was the one with strong WordPress experience or if that was #47. By application #60, everything blurs together. I know there are great people in this pile. I just can’t give each one the attention they deserve.
So I built something to help.
Starting the Conversation
Before I even opened Claude Code, I spent time with Claude Chat getting my thoughts in order. I dumped everything I knew about this hire: the job description, what RebelCode is about, our company culture, what success looks like for this role, what went well with previous hires, what went badly. Claude Chat helped me distill all of that into a clear, structured prompt that would actually work for building a tool.

The key context we captured:
- We need someone who builds WordPress plugins
- Strong PHP with actual OOP, not just procedural scripts
- React experience for our admin interfaces
- Proven remote work ability
- Timezone overlap with Europe
- Can they communicate clearly?
- Do they have a product mindset?
We also defined what success looks like. In 3 months, they had to be shipping features independently, and in 12 months, they’d become a full technical partner.
This isn’t a junior role, but it’s also not a $150k Silicon Valley position. We’re a bootstrapped company paying $40-45k for someone who wants to grow with us.
With that foundation ready, I took the prompt into Claude Code and started building.
What We Built
SCREEN is a full-stack app. React frontend, Node.js backend, PostgreSQL for storage, and Claude for the AI analysis. But the interesting part isn’t the tech stack. It’s how the system thinks about candidates.
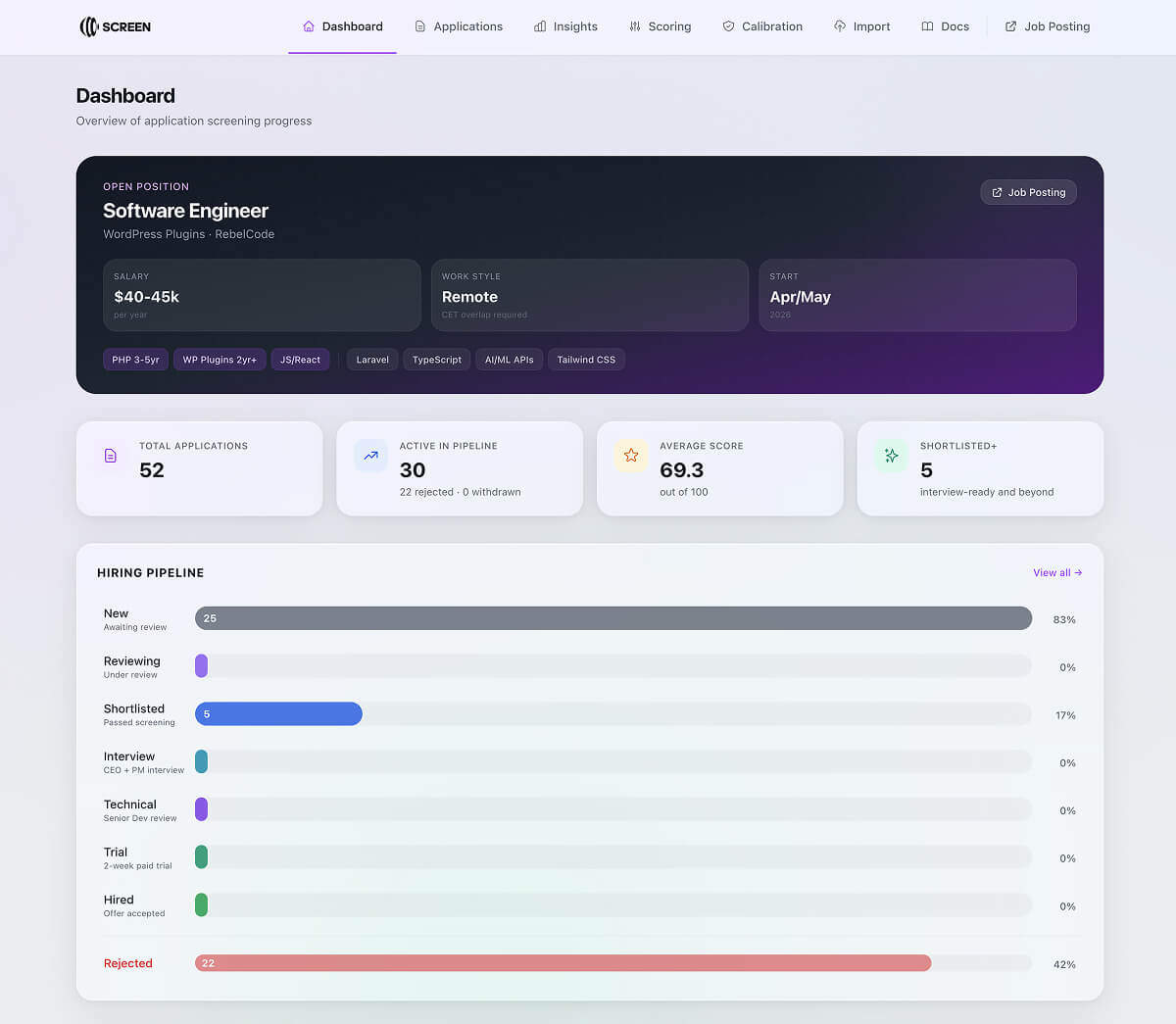
Every application gets scored across four dimensions:
- Technical Depth (0-30): Do they actually know WordPress plugin development? Is their PHP modern or stuck in 2010?
- Independence & Communication (0-25): Can they write clearly? Is their portfolio real work or just tutorials?
- Culture & Role Fit (0-25): Have they done remote work before? Do they understand we’re a product company?
- Practical Fit (0-20): Timezone, availability, did they actually submit the video we asked for?
The system also pulls in GitHub profiles automatically, analyzes video introductions for communication signals, and flags concerns like “claims 5 years WordPress experience but GitHub shows only theme customizations.”
The Part That Surprised Me
I expected the scoring to be useful. What I didn’t expect was how much the small features would matter.
The “Next Step Recommendation” turned out to be huge. Instead of looking at a profile and thinking “okay, what do I do with this person?” SCREEN just tells me.
Score of 87 with no red flags? “Move to Shortlist.”
Fair score but strong technical signals? “Review Technical Profile.”
Low score with multiple concerns? “Consider Rejecting.”
Each recommendation comes with reasoning.
The comparison view lets me put 2-4 candidates side by side and even generates an AI-powered analysis of how they stack up against each other. Who’s stronger technically? Who’s better for remote work? It surfaces tradeoffs I might not think to consider.
And the calibration feedback loop means I can tell the system “I disagree with this score”, and then see patterns over time. Is the AI consistently harsh on certain backgrounds? Or is it too lenient on others?
What I Actually Learned
Context matters more than prompts. The system works because I front-loaded it with everything about what we’re looking for. That time spent with Claude Chat before coding even started was probably the most valuable part. Without that clarity, it would just be generic resume screening.
AI as augmentation, not replacement. I still make every decision. SCREEN just makes sure I’m making them with full information and consistent criteria. It’s the difference between reading 200 applications tired at midnight versus having a colleague who already read them all and can brief me on each one.
Fairness through consistency. Every candidate gets evaluated against the same rubric, with the same attention. That’s actually fairer than me trying to maintain consistency across a week of reviews.
The details compound. Document viewers, bulk actions, interview question generators, score calibration. Individually small features, but together they transform “useful tool” into “how did I hire without this?”
The Result
What took days now takes hours. More importantly, I’m confident I’m catching the good candidates who might otherwise get lost in the pile.
The system flagged someone I would have passed over because of a modest overall presentation. Looking deeper, their WordPress.org profile showed contributions to well-maintained plugins with thousands of active installs.
It also caught someone who looked great on paper but had timezone incompatibility buried in their details and a video that raised communication concerns. Saved us both time.
SCREEN isn’t about removing humans from hiring. It’s about giving humans the support they need to hire well. A second pair of eyes that never gets tired, never loses the rubric, and always remembers what we’re actually looking for.
Leave a Reply